懒人听书 v8.3.1.1
懒人听书 v8.3.1.1
 CAJViewer 官方版 v8.1.73.0
CAJViewer 官方版 v8.1.73.0
 书旗小说阅读器 电脑版 v12.0.0.198
书旗小说阅读器 电脑版 v12.0.0.198
 PowerPoint Reader(PPT阅读器) 官方版 v2.0
PowerPoint Reader(PPT阅读器) 官方版 v2.0
 金舟PDF阅读器 最新版 v2.1.7.0
金舟PDF阅读器 最新版 v2.1.7.0
 一元三次方程计算器 官方版 v1.0
一元三次方程计算器 官方版 v1.0
 汉王PDF OCR官方版是一款可以帮助用户进行orc文字识别的软件。汉王PDF
OCR最新版持处理灰度、彩色、黑白三种色彩的BMP、TIF、JPG、PDF多种格式的图像文件。汉王PDF
OCR官方版具有TXT、RTF、HTM和XLS多种输出格式,并有所见即所得的版面还原功能。 软件界面简洁,操作简便,易于上手。
汉王PDF OCR官方版是一款可以帮助用户进行orc文字识别的软件。汉王PDF
OCR最新版持处理灰度、彩色、黑白三种色彩的BMP、TIF、JPG、PDF多种格式的图像文件。汉王PDF
OCR官方版具有TXT、RTF、HTM和XLS多种输出格式,并有所见即所得的版面还原功能。 软件界面简洁,操作简便,易于上手。
更新日志
对部分功能进行了优化
软件特色
汉王OCR文字识别软件具有识别正确率高,识别速度快的特点。
支持批量处理功能,避免了单页处理的麻烦。
支持处理灰度、彩色、黑白三种色彩的BMP、TIF、JPG、PDF多种格式的图像文件;
可识别简体、繁体和英文三种语言;
具有简单易用的表格识别功能;
具有TXT、RTF、HTM和XLS多种输出格式,并有所见即所得的版面还原功能。
FAQ
OCR文字识别技术是什么?
光学字符识别(英语:Optical Character Recognition, OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。OCR的概念是在1929年由德国科学家Tausheck最先提出来,并申请了专利。后来美国科学家Handel也提出了利用技术对文字进行识别的想法。国内最早的OCR商业应用是由中国科学家王庆人教授在南开大学开发出来的,并在美国市场投入商业使用。
安装步骤
1、双击从本站下载的安装包,打开安装向导,单击【下一步】。
2、同意许可证协议,单击【是】。

3、单击【浏览】选择软件安装位置,单击【下一步】。

4、耐心等待一下软件安装。
5、安装完成,单击【完成】就可以使用软件了。
使用技巧
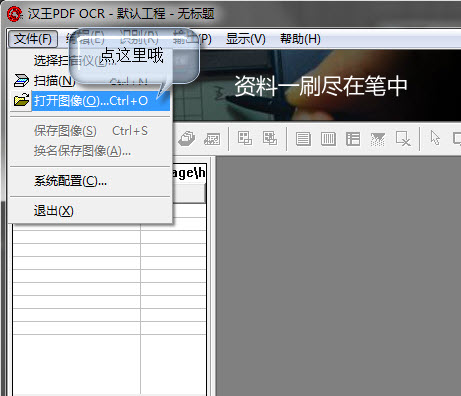
1、在主界面任务栏左上角【文件】选项中选择打开图像,快捷键Ctrl+O。
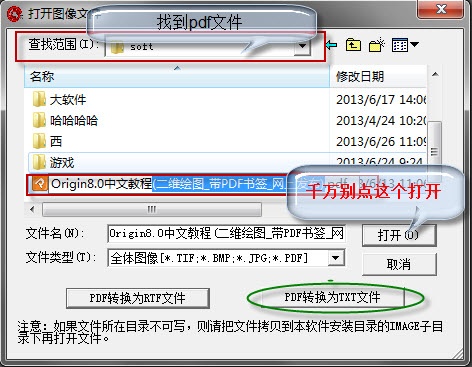
2、查找您需要转换的pdf文件,注意:不需要点打开,你只需要选中就行,然后点击【pdf转换为TXT文件】。
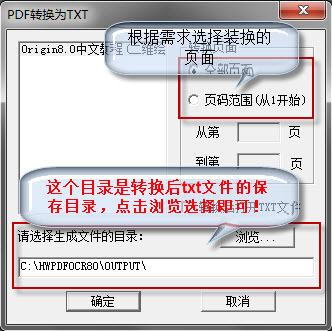
3、选择你需要转换的页面,也就是你pdf文件里边的内容你需要转换的部分,默认是全部转换。然后选择转换后txt文版的保存地址,点击【浏览】选择文件夹。
4、转换完成,时间根据内容的多少来确定。