JetBrains PhpStorm 最新版 v2020.2.1
JetBrains PhpStorm 最新版 v2020.2.1
 PyCharm 专业版 v2023.1.1
PyCharm 专业版 v2023.1.1
 Rider 2019 最新版
Rider 2019 最新版
 UltraEdit 官方版 v29.00
UltraEdit 官方版 v29.00
 phpstorm 2019 官方版
phpstorm 2019 官方版
 IDM UEStudio 中文版 v19.20.0.38
IDM UEStudio 中文版 v19.20.0.38
 weka软件是一款小巧专业的数据挖掘工具。weka软件功能强劲,并且开源免费,软件具备了海量数据挖掘的算法,可以让用户轻松找到适合的数据挖掘方式,可以对数据进行预处理、分类、回归、聚类、关联规则等等,让数据挖掘更加快捷。
weka软件是一款小巧专业的数据挖掘工具。weka软件功能强劲,并且开源免费,软件具备了海量数据挖掘的算法,可以让用户轻松找到适合的数据挖掘方式,可以对数据进行预处理、分类、回归、聚类、关联规则等等,让数据挖掘更加快捷。
| 相关软件 | 版本说明 | 下载地址 |
|---|---|---|
| .net framework | v4.0.30319 | 查看 |
|
Visual Basic |
简体中文企业版 | 查看 |
|
VC++6.0 |
英文版 | 查看 |
|
猿编程客户端 |
官方版 | 查看 |
特色介绍
1、可以处理一个数据库的查询结果
2、weka软件支持相同功能的命令行,或是一种基于组件的知识流接口
3、集成自己的算法甚至借鉴它的方法自己实现可视化工具都很简单
4、技术基于假设数据是以一种单个文件或关联的
5、使用Java的数据库链接能力可以访问SQL数据库
主要功能
1、对数据进行预处理、分类、回归、聚类、关联规则
2、在新的交互界面上的可视化
3、使用Java的数据库链接能力可以访问SQL数据库
4、可以集成自己的算法甚至借鉴它的方法自己实现可视化工具
安装方法
1、在本站下载weka软件安装包,解压缩后双击“weka-3-8-5-azul-zulu-windows.exe”程序进入欢迎安装界面,点击“Next>”进入下一步
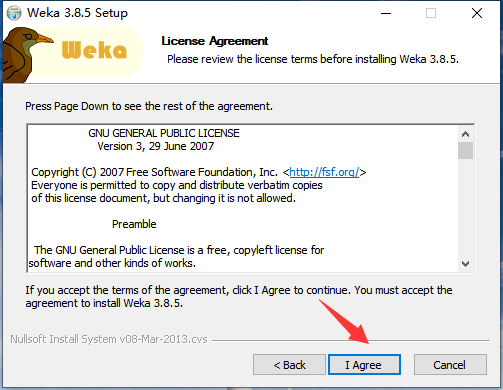
2、仔细查看软件许可证协议,点击“I Agree”同意许可证协议
3、选择需要安装的组件,我们默认即可,点击“Next>”继续
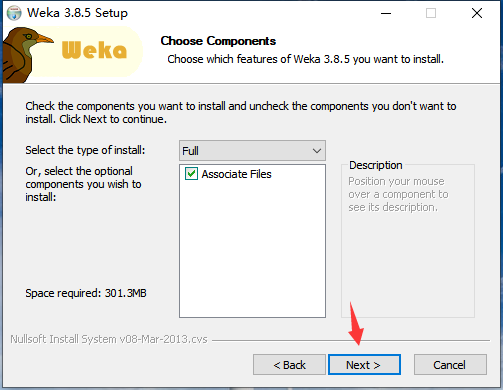
4、选择安装位置,软件默认安装在“C:/Program Files/Weka-3-8-5”,我们点击“Browse...”可以选择其它位置安装
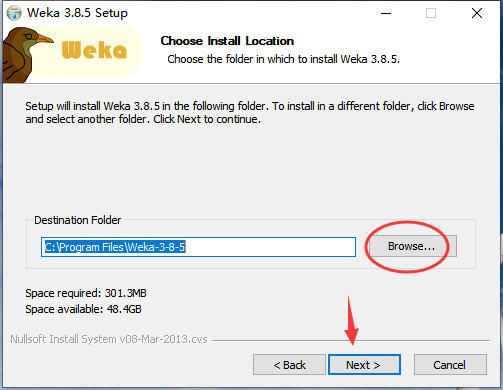
5、选择开始菜单文件夹位置,我们也可以选择不创建开始菜单文件夹,点击“Install”开始安装
6、软件正在安装中,请等待
7、软件安装成功,点击“Finish”退出安装向导
使用说明
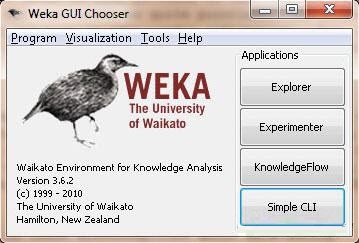
1、在启动WEKA时,会弹出GUI选择器,让您选择使用WEKA和数据的四种方式。选择Explorer选项已经足够。
2、weka是基于java,用于数据挖掘和知识分析一个平台。从海量数据中发掘其背后隐藏的种种关系。
3、数据创建完成后,就可以开始创建我们的回归模型了。启动 WEKA,然后选择 Explorer。将会出现 Explorer 屏幕,其中 Preprocess 选项卡被选中。选择 Open File 按钮并选择在上一节中创建的 ARFF 文件。
常见问题
我可以使用CSV文件吗?
是,你可以。但要注意,有在ARFF文件比较多的缺点(Weka的默认文件格式):
不能增量读取CSV文件。为了确定列是数字还是标称,所有行都需要先检查。arff文件包含标题定义属性,即内部数据结构可以设置正确的阅读实际数据之前。
列车和测试集可能不兼容。使用CSV文件作为火车和测试集可以是一个令人沮丧的练习。从CSV文件不包含任何信息的属性,WEKA需要确定名义属性本身的标签。不仅是这些标签出现的顺序创建名义属性不同(“1,2,3”VS“1”),但它并不能保证所有的标签在火车上出现,也出现在测试集(“1,2,3,4”与“天”),反之亦然。
我能在WEKA查看我的路径?
是,你可以。刚开始的simplecli并发出以下命令:
java weka.core.systeminfo
找物业java.class.path,其中列出了classpath WEKA开始
运行中的问题解决方法
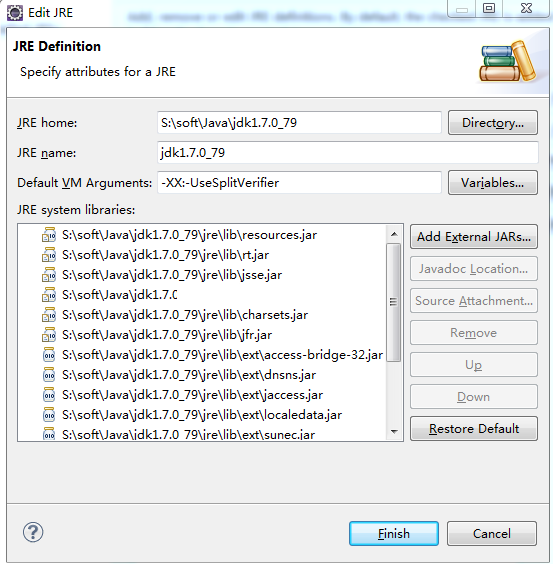
问题描述:java.lang.VerifyError: Inconsistent stackmap frames at branch target 1027
解决方法:Installed JREs->Edit->Default VM Arguments加上-XX:-UseSplitVerifier
问题描述:Trying to add database driver (JDBC): jdbc.idbDriver - Error, not in CLASSPATH?
解决方法:
1、找到DatabaseUtils.java文件,修改line:83,public final static String PROPERTY_FILE = "weka/experiment/DatabaseUtils.props ";->DatabaseUtils.props.mysql(这里我用的是mysql),修改line:184,去掉jdbc.idbDriver,String drivers = PROPERTIES.getProperty("jdbcDriver");
2、找到DatabaseUtils.props.mysql文件,修改jdbcURL
3、找到目录Javajdk1.7.0_79jrelibext,添加jdbc驱动jar或者配置CLASSPATH