iFonts字体助手 最新版 v2.4.7
iFonts字体助手 最新版 v2.4.7
 小智桌面 3.3.1.8
小智桌面 3.3.1.8
 神奇电商宝贝下载软件 电脑版 v3.0.0.285
神奇电商宝贝下载软件 电脑版 v3.0.0.285
 ABBYY FineReader 官方版 v11.0.513.194
ABBYY FineReader 官方版 v11.0.513.194
 MathType v6.9
MathType v6.9
 Xshell Portable 官方版 v6 6.0.011
Xshell Portable 官方版 v6 6.0.011
 ABBYY FineReader中文版是世界排名第一的OCR文字识别工具,提供高效和精准的文档识别、数据提取解决方案,ABBYY FineReader中文版支持多国字符和彩色文件识别,主要用于将扫描图像、图片型PDF转化成可编辑的文本。
ABBYY FineReader中文版是世界排名第一的OCR文字识别工具,提供高效和精准的文档识别、数据提取解决方案,ABBYY FineReader中文版支持多国字符和彩色文件识别,主要用于将扫描图像、图片型PDF转化成可编辑的文本。
软件特色
OCR识别精度达到99%的先进OCR识别技术可以使您无需录入和排版就可以数字化您的文档;
ADRT技术可以完美还原文档的逻辑结构和格式;
先进的数码相机OCR识别技术;
与PDF文件广泛协同;
通过预先定义的快速OCR识别任务来处理文件。
FAQ
如何不通过识别将文档保存为PDF文件?
答:若要不通过识别文本将图像保存为PDF文件,打开文件菜单,选择保存图像选项,在图像另存为对话框中,从另存为类型下拉列表中选择PDF并保存图像。
ABBYY FineReader 12能识别包含非常规符号(象形符号、©和®符号等)的文本吗?
答:ABBYY FineReader 12可以识别所有的Unicode 符号(相关文章请参考ABBYY FineReader 12如何识别包含非常规符号的文本)。
ABBYY FineReader 12能识别非标准和装饰字体的文本吗?
答:可以使用ABBYY FineReader Professional的训练识别功能识别非标准字体,该功能可以让你创建自定义模式识别非常规字体。
若要启用训练识别功能,打开工具菜单,选择选项项,点击读取选项卡,勾选通过训练读取或训练用户模式选项。
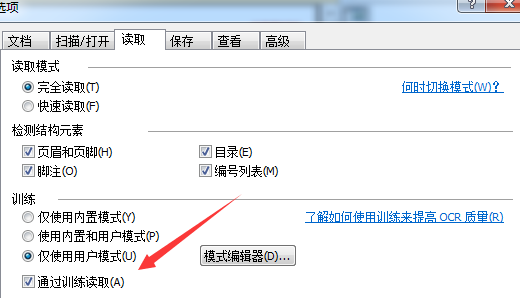
可以在ABBYY FineReader 12帮助的高级功能>通过训练识别章节中找到更多关于通过训练识别的信息。
激活软件过程中为什么收到以下错误信息:该序列号无法自动激活?
答:激活软件过程中出现以下错误信息:该序列号无法自动激活,你可能会违反终端用户许可协议尝试在更多电脑上激活程序。
试图激活的程序序列号被封锁时会出现这种错误提示,这种情况可以由以下几种原因造成:
1、此序列号激活过于频繁;
2、此序列号被用来升级程序;
3、违反了终端用户许可协议。
关于ABBYY FineReader的更多内容,请点击进入ABBYY中文服务中心,查找您需要的信息。
安装步骤
一、在本站下载最新版ABBYY FineReader,双击安装。
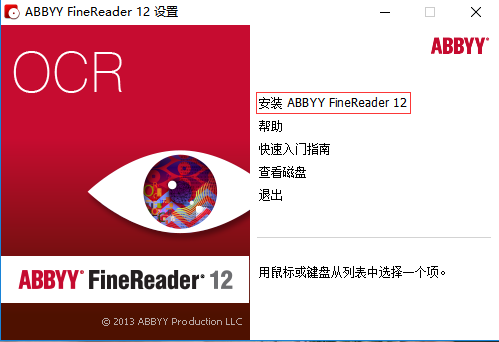
二、点击安装后,点击确定。
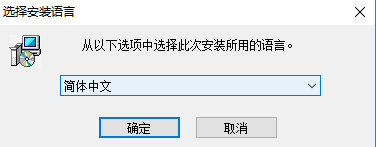
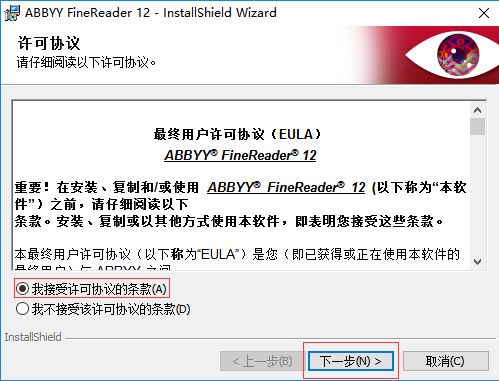
三、点击接受条款。
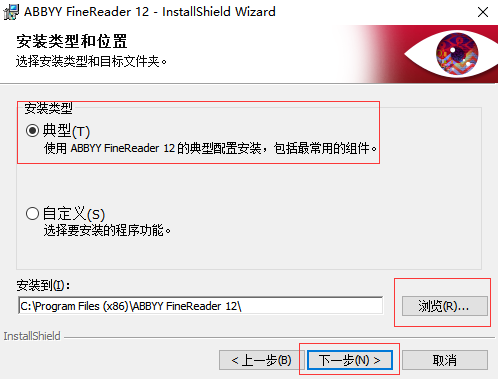
四、选择安装类型,第一次安装就选择典型,然后点击【浏览】,选择软件的安装路径;或者直接点击【下一步】,软件会安装在默认的位置。
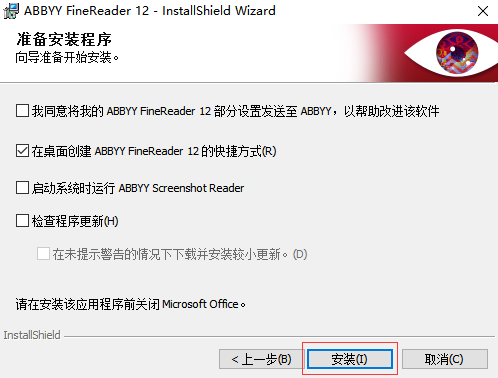
五、耐心等待一会,软件就安装好了。
使用技巧
使用ABBYY FineReader 14创建Excel电子表格
转换一个或多个文件
1、打开FineReader 14软件,点击‘打开’选项卡,然后点击‘转换为Microsoft Excel’。
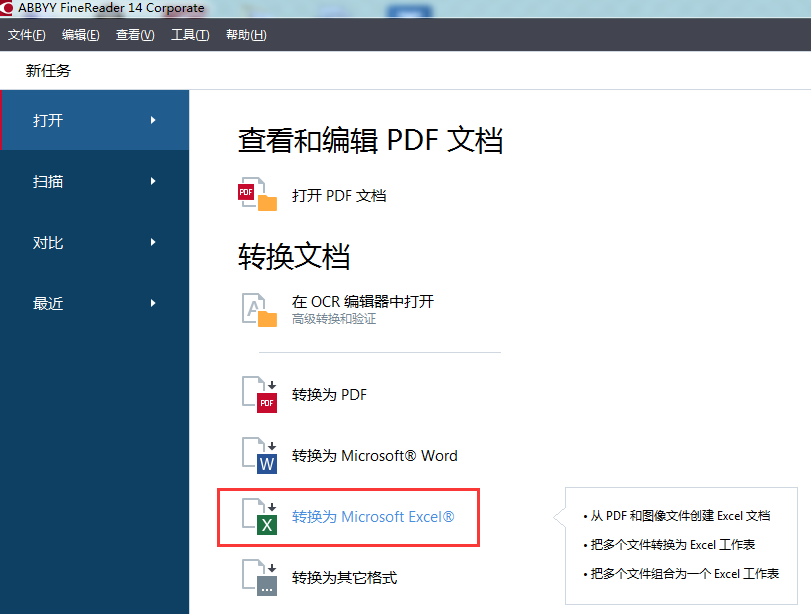
2、在打开的对话框中,选择一个或多个文件进行转换。
3、指定转换设置,这些设置将决定输出文档的外观和属性。
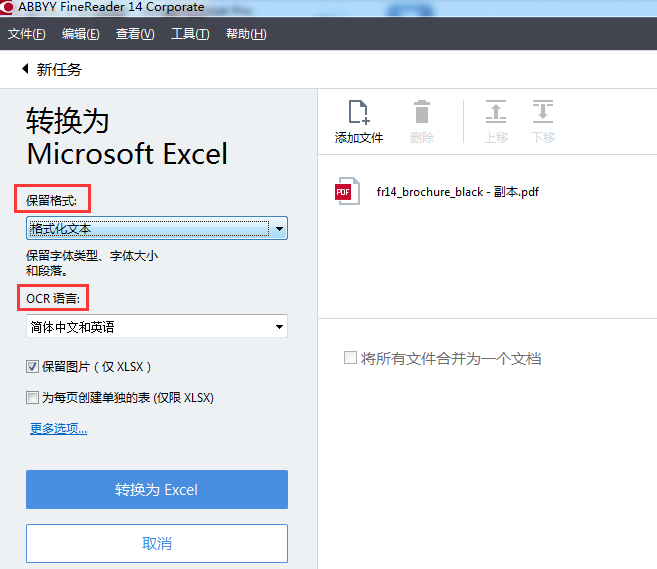
保留格式
选择合适的设置取决于你准备如何使用输出的文档:
•格式化文本
保留字体类型、字体大小和段落格式。
•纯文本
只保留段落格式,同一字体将通篇使用。
OCR语言
选择文档语言。ABBYY FineReader 14可以识别单一语言和多语言的文档,对于多语言文档,你需要选择多个OCR语言。
保留图片(仅XLSX)
如果你想保留输出文档中的图片,就勾选该选项。
为每页创建单独的表(仅XLSX)
如果想从原文档的每页创建单独的Microsoft Excel电子表格,就勾选此选项。
4、根据需要添加或删除文件。
5、点击‘转换为Excel’按钮。
6、为输出的文件指定一个目标文件夹。
任务完成之后,最终的Excel文件将位于你指定的文件夹里。
合并文件
1、打开软件,点击‘打开’选项卡,然后点击‘转换为Microsoft Excel’。
2、在打开的对话框中,选择要转换的文件。
3、指定转换设置。
4、根据需要添加或删除文件。
5、按照需要的顺序排列文件,勾选‘将所有文件合并为一个文档’选项。
6、点击‘转换为Excel’按钮。
7、为输出的文件命名并选择目标文件夹。